| 基于文字局部结构相似度量的开放集文字识别方法 |
| |
| 引用本文: | 刘畅, 杨春, 殷绪成. 基于文字局部结构相似度量的开放集文字识别方法. 自动化学报, 2024, 50(10): 1977−1987 doi: 10.16383/j.aas.c230545 |
| |
| 作者姓名: | 刘畅 杨春 殷绪成 |
| |
| 作者单位: | 1.北京科技大学计算机与通信工程学院 北京 100083 |
| |
| 基金项目: | 新一代人工智能国家科技重大专项 (2020AAA0109701), 国家杰出青年科学基金 (62125601), 国家自然科学基金 (62076024)资助 |
| |
| 摘 要: | 
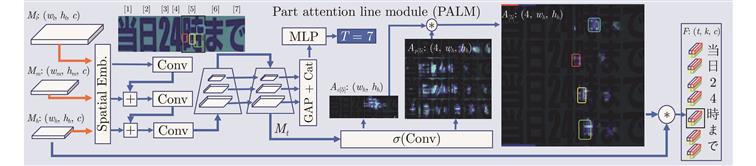
开放集文字识别 (Open-set text recognition, OSTR) 是一项新任务, 旨在解决开放环境下文字识别应用中的语言模型偏差及新字符识别与拒识问题. 最近的 OSTR 方法通过将上下文信息与视觉信息分离来解决语言模型偏差问题. 然而, 这些方法往往忽视了字符视觉细节的重要性. 考虑到上下文信息的偏差, 局部细节信息在区分视觉上接近的字符时变得更加重要.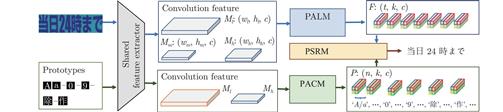
本文提出一种基于自适应字符部件表示的开放集文字识别框架, 构建基于文字局部结构相似度量的开放集文字识别方法, 通过对不同字符部件进行显式建模来改进对局部细节特征的建模能力. 与基于字根 (Radical) 的方法不同, 所提出的框架采用数据驱动的部件设计, 具有语言无关的特性和跨语言泛化识别的能力. 此外, 还提出一种局部性约束正则项来使模型训练更加稳定. 大量的对比实验表明, 本文方法在开放集、传统闭集文字识别任务上均具有良好的性能.
|
| 关 键 词: | 开放集文字识别 开放集学习 泛用零样本学习 组成学习 |
| 收稿时间: | 2023-09-04 |
|
| 点击此处可从《自动化学报》浏览原始摘要信息 |
|
点击此处可从《自动化学报》下载免费的PDF全文 |
|