| 语音驱动说话数字人视频生成方法综述 |
| |
| 引用本文: | 刘颖, 李济廷, 柴瑞坤, 位纪伟, 杨阳. 语音驱动说话数字人视频生成方法综述[J]. 电子科技大学学报, 2024, 53(6): 911-921. DOI: 10.12178/1001-0548.2024156 |
| |
| 作者姓名: | 刘颖 李济廷 柴瑞坤 位纪伟 杨阳 |
| |
| 作者单位: | 1.军事科学院 军队政治工作研究院,北京 100166;2.电子科技大学 计算机科学与工程学院,成都 611731 |
| |
| 基金项目: | 国家自然科学基金(62306067) |
| |
| 摘 要: | 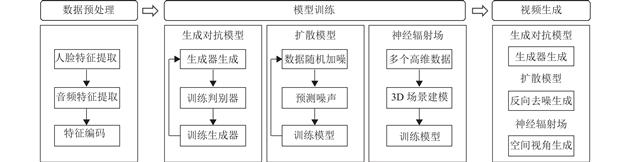
近年来,深度学习技术的飞速发展极大地推动了虚拟数字人技术的进步,尤其是在说话数字人视频生成方面。该领域的研究在视频翻译、电影制作和虚拟助手等多个场景中展现出广阔的应用前景。该文对当前语音驱动说话数字人视频生成方法及研究现状进行了梳理与总结,并深入探讨了关键技术、数据集以及评估策略。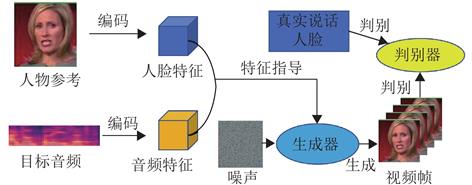
在关键技术方面,生成对抗模型、扩散模型和神经辐射场等人工智能技术均发挥了重要作用。数据集的规模和多样性对于模型训练至关重要,而评估策略的完善则有助于更加客观地评价生成效果。说话数字人视频生成技术将继续面临众多挑战与机遇,期待该领域能够持续创新与发展,为人类社会带来更多便捷与乐趣。

|
| 关 键 词: | 说话数字人 视频生成 生成对抗模型 扩散模型 神经辐射场 多模态融合 |
| 收稿时间: | 2024-06-30 |
| 修稿时间: | 2024-08-29 |
|
| 点击此处可从《电子科技大学学报(自然科学版)》浏览原始摘要信息 |
|
点击此处可从《电子科技大学学报(自然科学版)》下载全文 |
|