| 基于中粒度模型的视频人体姿态估计 |
| |
| 引用本文: | 史青宣, 邸慧军, 陆耀, 田学东. 基于中粒度模型的视频人体姿态估计. 自动化学报, 2018, 44(4): 646-655. doi: 10.16383/j.aas.2018.c160847 |
| |
| 作者姓名: | 史青宣 邸慧军 陆耀 田学东 |
| |
| 作者单位: | 1.北京理工大学计算机学院 北京 100081;;2.河北大学网络空间安全与计算机学院 保定 071000;;3.智能信息技术北京市重点实验室 北京 100081 |
| |
| 基金项目: | 河北省高等学校科学技术研究重点项目ZD2017208国家自然科学基金61375075国家自然科学基金9142020013国家自然科学基金61273273 |
| |
| 摘 要: | 
人体姿态估计是计算机视觉领域的一个研究热点,在行为识别、人机交互等领域均有广泛的应用.本文综合粗、细粒度模型的优点,以人体部件轨迹片段为实体构建中粒度时空模型,通过迭代的时域和空域交替解析,完成模型的近似推理,为每一人体部件选择最优的轨迹片段,拼接融合形成最终的人体姿态序列估计.为准备高质量的轨迹片段候选,本文引入全局运动信息将单帧图像中的最优姿态检测结果传播到整个视频形成轨迹,然后将轨迹切割成互相交叠的固定长度的轨迹片段.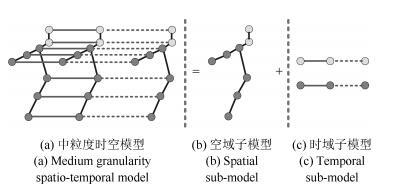
为解决对称部件易混淆的问题,从概念上将模型中的对称部件合并,在保留对称部件间约束的前提下,消除空域模型中的环路.在三个数据集上的对比实验表明本文方法较其他视频人体姿态估计方法达到了更高的估计精度.

|
| 关 键 词: | 人体姿态估计 中粒度模型 马尔科夫随机场 隐马尔科夫模型 |
| 收稿时间: | 2016-12-27 |
|
| 点击此处可从《自动化学报》浏览原始摘要信息 |
|
点击此处可从《自动化学报》下载免费的PDF全文 |
|