| 引用本文: | 康潇, 刘兴波, 卢鹏宇, 赵志杰, 聂秀山, 王少华, 尹义龙. 双重结构保持的在线跨模态哈希[J]. 计算机研究与发展, 2024, 61(11): 2923-2936. DOI: 10.7544/issn1000-1239.202330433 |
| 摘 要: | 
近年来,在线跨模态哈希因其能处理更为贴近现实的流数据场景而受到广泛关注. 虽然取得了不错的进展,但现有方法大都依赖准确清晰的数据标记. 目前,针对无监督学习模式下在线跨模态哈希的研究相对较少,还有很多问题有待解决. 例如,新到达的数据流通常规模较小,因此常常存在分布不平衡的现象. 而现有模型极少关注这个问题,导致模型对离群样本敏感,鲁棒性较差. 并且,现有方法大都关注样本的整体结构而忽视了邻域信息对于生成公共哈希码的帮助.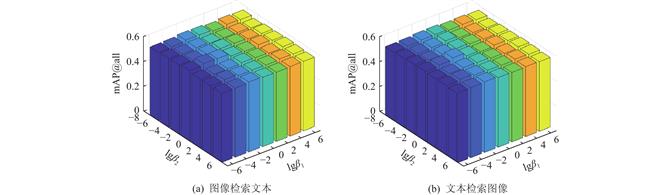
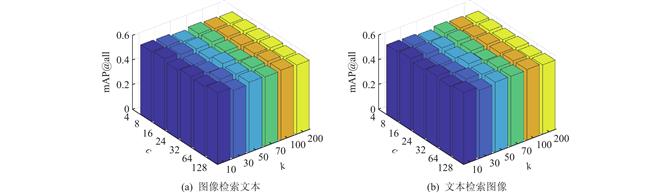
为了解决上述问题,提出了基于双重结构保持的无监督在线跨模态哈希方法,称为SPOCH(structure preserving online cross-modal hashing). 该方法的基本思想是同时挖掘样本空间的全局结构信息和邻域结构信息来生成相应的公共表示,用以指导哈希码和哈希函数的学习. 针对全局结构的学习,引入$ {L_{2,1}} $范数取代$ {L_2} $范数来约束损失函数,利用$ {L_{2,1}} $范数结构化稀疏的性质缓解模型对离群样本的敏感性;针对邻域结构的学习,利用多模态融合的邻域样本进行样本重构,使得所学公共表示更好地表征多模态信息. 此外,为了缓解遗忘问题,提出在新旧数据上联合优化,并设计相应的更新策略提高算法的训练效率,实现在线检索. 在2个广泛使用的跨模态检索数据集上进行的实验结果表明,较现有最先进的无监督在线跨模态哈希方法,SPOCH在可比较甚至更短的训练时间内取得了更优的检索精度,验证了所提方法的有效性.
|