| 基于深度强化学习的掼蛋扑克博弈求解 |
| |
| 引用本文: | 葛振兴, 向帅, 田品卓, 高阳. 基于深度强化学习的掼蛋扑克博弈求解[J]. 计算机研究与发展, 2024, 61(1): 145-155. DOI: 10.7544/issn1000-1239.202220697 |
| |
| 作者姓名: | 葛振兴 向帅 田品卓 高阳 |
| |
| 作者单位: | 1.计算机软件新技术国家重点实验室(南京大学) 南京 210023;2.上海大学计算机工程与科学学院 上海 200444;3.南京大学深圳研究院 广东深圳 518057 |
| |
| 基金项目: | 国家重点研发计划项目(2018AAA0100905);;国家自然科学基金项目(62192783,62276142,62206166);;上海市扬帆计划项目(23YF1413000)~~; |
| |
| 摘 要: | 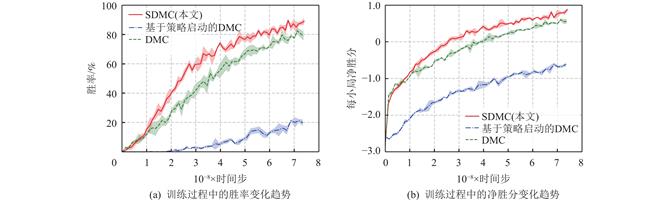
在不确定信息的复杂环境下进行决策是现实中人们经常面对的困难之一,因此具有能够进行良好决策的能力被视为人工智能的重要能力之一. 而游戏类型的博弈作为对现实世界的一种高度抽象,具有良定义、易检验算法优劣等特点,成为研究的主流. 其中以掼蛋为代表的扑克类博弈不仅具有他人手牌未知这样的难点,还由于可选出牌动作与他人手牌情况数量庞大等特点,难以进行高效求解. 因此,提出了一种软深度蒙特卡洛(soft deep Monte Carlo,SDMC)求解方法. 该方法能够更好地融合领域知识,加快策略学习速度,并采用软动作采样策略调整实时决策,提升策略胜率. 所提出的SDMC方法训练出的策略模型参加第2届“中国人工智能博弈算法大赛”时获得冠军. 与第1届比赛冠军策略和第2届其他策略模型的实验对比证明了该方法在解决掼蛋扑克博弈中的有效性.
|
| 关 键 词: | 非完美信息 深度强化学习 多智能体系统 软深度蒙特卡洛方法 扑克博弈 |
| 收稿时间: | 2022-08-08 |
| 修稿时间: | 2023-04-06 |
|
| 点击此处可从《计算机研究与发展》浏览原始摘要信息 |
|
点击此处可从《计算机研究与发展》下载免费的PDF全文 |
|