| 基于多域VQGAN的文本生成国画方法研究 |
| |
| 作者姓名: | 孙泽龙 杨国兴 温静远 费楠益 卢志武 文继荣 |
| |
| 作者单位: | 中国人民大学 高瓴人工智能学院, 北京 100872;中国人民大学 信息学院, 北京 100872 |
| |
| 基金项目: | 国家自然科学基金(61976220,61832017);北京高等学校卓越青年科学家计划(BJJWZYJH012019100020098) |
| |
| 摘 要: | 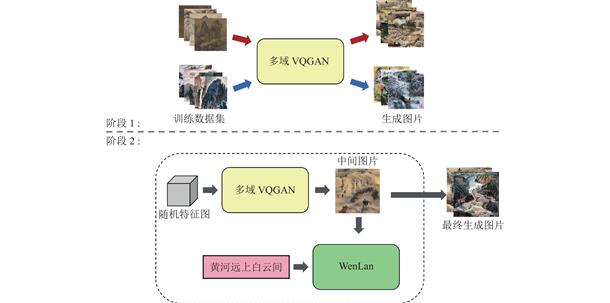
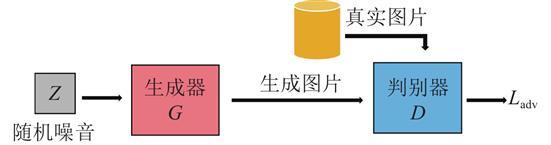
随着生成式对抗网络的出现,从文本描述合成图像最近成为一个活跃的研究领域.然而,目前文本描述往往使用英文,生成的对象也大多是人脸和花鸟等,专门针对中文和中国画的研究较少.同时,文本生成图像任务往往需要大量标注好的图像文本对,制作数据集的代价昂贵.随着多模态预训练的出现与推进,使得能够以一种优化的方式来指导生成对抗网络的生成过程,大大减少了对数据集和计算资源的需求.
提出一种多域VQGAN模型来同时生成多种域的中国画,并利用多模态预训练模型WenLan来计算生成图像和文本描述之间的距离损失,通过优化输入多域VQGAN的隐空间变量来达到图片与文本语义一致的效果.对模型进行了消融实验,详细比较了不同结构的多域VQGAN的FID及R-precisoin指标,并进行了用户调查研究.结果表示,使用完整的多域VQGAN模型在图像质量和文本图像语义一致性上均超过原VQGAN模型的生成结果.
|
| 关 键 词: | 文本生成图像 多域生成 中国画生成 |
| 收稿时间: | 2022-04-16 |
| 修稿时间: | 2022-05-29 |
| 本文献已被 万方数据 等数据库收录! |
| 点击此处可从《软件学报》浏览原始摘要信息 |
|
点击此处可从《软件学报》下载免费的PDF全文 |
|